
- Home
- India
- World
- Premium
- THE FEDERAL SPECIAL
- Analysis
- States
- Perspective
- Videos
- Sports
- Education
- Entertainment
- Elections
- Features
- Health
- Business
- Series
- In memoriam: Sheikh Mujibur Rahman
- Bishnoi's Men
- NEET TANGLE
- Economy Series
- Earth Day
- Kashmir’s Frozen Turbulence
- India@75
- The legend of Ramjanmabhoomi
- Liberalisation@30
- How to tame a dragon
- Celebrating biodiversity
- Farm Matters
- 50 days of solitude
- Bringing Migrants Home
- Budget 2020
- Jharkhand Votes
- The Federal Investigates
- The Federal Impact
- Vanishing Sand
- Gandhi @ 150
- Andhra Today
- Field report
- Operation Gulmarg
- Pandemic @1 Mn in India
- The Federal Year-End
- The Zero Year
- Science
- Brand studio
- Newsletter
- Elections 2024
- Events
- Home
- IndiaIndia
- World
- Analysis
- StatesStates
- PerspectivePerspective
- VideosVideos
- Sports
- Education
- Entertainment
- ElectionsElections
- Features
- Health
- BusinessBusiness
- Premium
- Loading...
Premium - Events

What the first gapless human genome sequence can tell us about ourselves

The first complete readout of all the 3.055 billion letters, a text long enough to fill hundreds of books, has been sequenced. Led by Karen Miga, assistant professor of biomolecular engineering at UC Santa Cruz, Adam Phillippy at the National Human Genome Research Institute, and their colleagues at the ‘Telomere-to-Telomere (T2T) Consortium’, the new sequence has added nearly...
The first complete readout of all the 3.055 billion letters, a text long enough to fill hundreds of books, has been sequenced. Led by Karen Miga, assistant professor of biomolecular engineering at UC Santa Cruz, Adam Phillippy at the National Human Genome Research Institute, and their colleagues at the ‘Telomere-to-Telomere (T2T) Consortium’, the new sequence has added nearly 200 million base pairs to the 2013 version of the human genome sequence. In the process, the researchers have discovered an additional 115 genes that code for proteins making the total number of identified protein-coding genes in the human genome 19,969. Further, the complete genome sequence is expected to provide new insights into health and what makes humans distinct.
“Telomeres are the regions at the ends of chromosomes, and the team had sequenced, telomere to telomere that is ‘end to end’ of the chromosome without any gap. This new ‘reference’ sequence, dubbed T2T-CHM13, contains the genomic sequence of all the 22 human chromosomes without any gap, plus the X chromosome,” explains prof S Krishnaswamy, former head of Biotechnology at Madurai Kamaraj University and presently Treasurer of All India Peoples Science Movement.
Blueprint of life
From the salivary amylase enzyme that aids digestion of food, melatonin, a hormone that helps to control our sleep/wake cycles, haemoglobin to transport oxygen in the body, myosin that enables the muscle movement, collagen and elastin, which provide structure to the cell, antibodies that fight the invading pathogen, ferritin that store iron, to serotonin a neurotransmitter that aids signalling, proteins play a crucial role in the biology of life. One estimate says that the human body produces anywhere between 80,000 and 4,00,000 types of proteins.
The instructions for making these proteins are encrypted in the genome in the form of DNA (deoxyribonucleic acid) molecules. One way to describe the genome is to compare it with a big fat cookbook. In this analogy, a genome is an anthology containing the DNA instructions for life. The book of life is written in a language consisting of four letters (nucleotides), organised into chapters (chromosomes). Just like the Mughlai, Punjabi, Chinese, Continental, South Indian, and Eastern cuisine are grouped in a cookbook, in humans, the entire genome is organised into 23 pairs of chromosomes. Each of the paragraphs (gene), that is regions of DNA, in the chromosome, describes how to make a particular protein that allows an organism to function. For example, the gene coding for proinsulin is located at the human chromosome 11 while the gene encoding the immunoglobulin antibody is located on human chromosome 14.
The DNA encodes the building plan for any living organism. Cellular organs read the DNA blueprint to cook various proteins. Every cell does not produce all the 4,00,000+ proteins. Just like a Punjabi restaurant usually does not offer continental cuisine, cells in the human body are specialised. Some housekeeping proteins are produced by almost all the cells, the insulin is produced exclusively by Beta cells in the pancreas and the specialised white blood cells called B lymphocytes (or B cells) produce immunoglobulin antibodies. The breakfast menu is usually not available after 10 am, likewise, certain proteins are produced when the organism is young or old, during daytime or night, or during specific seasons. The regulatory instructions for when, where, and how much to produce are also encoded in the genome.
Language of life
The English language has 26 letters in the alphabet, but the language of life has just four; ‘A, C, G, T’, which is an acronym for the four types of nucleotides found in a DNA molecule: adenine (A), cytosine (C), guanine (G), and thymine (T). The DNA molecules are made of two twisted, paired strands. An A of a strand always pairs with a T on the opposite strand and a C with a G. On the other hand, the RNA molecule is a single strand and the base called uracil (U) replaces thymine (T).
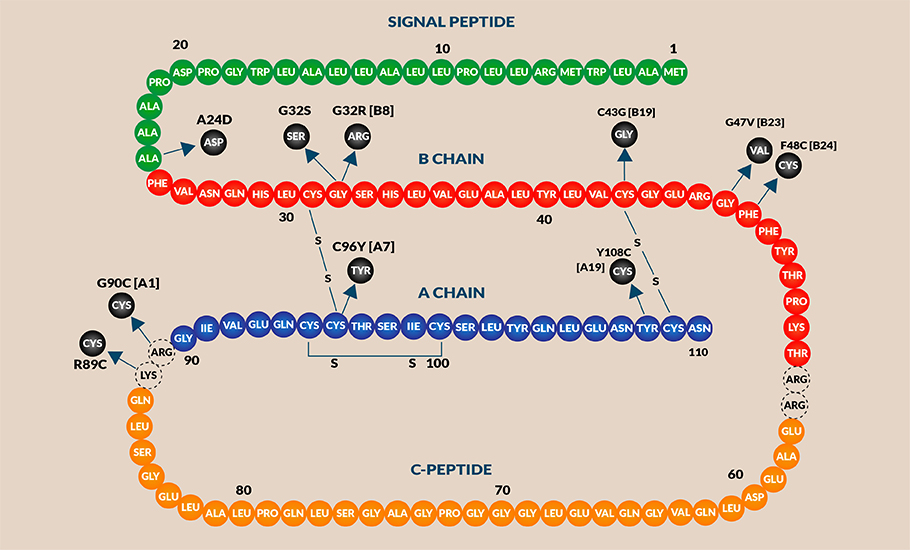
It is said that the King James authorised Bible has a staggering 3,116,480 letter characters grouped into 7,83,137 words. The book of human life, the genome that encodes the instructions needed to develop and direct the activities of each and every cell in the body, is a list of about 3,117,275,501 nucleotides letters embedding 19,969 genes. In comparison, SARS-CoV-2’s genome, an RNA is just 29,811 nucleotides long while a ‘typical’ bacterial genome is around 5 million base pairs.
In English, ‘I’ is a single letter word; and ‘pneumonoultramicroscopicsilicovolcanoconiosis’ with 46 characters is the longest word in any of the major dictionaries. However, in genomic language, each word is three-lettered. Each combination of three nucleotide alphabets distinctly codes for one of the specific 20 amino acids. For example, the sequence ATG in the DNA strand encodes the amino acid methionine (Met), GCC implies alanine and CCC encodes proline. These 20 amino acids combine in different ways to make various proteins in our body, from Glutathione, which has just three amino acids to Titin, the largest protein with a train of 27,000 amino acids.
The genome sequence, at the first glance would look gibberish, but for the ribosome, the protein factory of the cell, it is biochemical instructions for making a particular protein. For example, the first 36 letters of the human proinsulin gene read ATG GCC CTG TGG ATG CGC CTC CTG CCC CTG CTG GCG. The ribosome along with the transfer RNA (tRNA) picks the correct amino acid corresponding to each of the three letters and fastens them into a chain. For example, corresponding to ATG tRNA picks up methionine (Met) and for GCC the amino acid alanine. Likewise, by stringing these amino acids one by one the ribosome helps prepare a chain of amino acids- Met-Ala-Leu-Trp-Met-Arg-Leu-Leu-Pro-Leu-Leu-Ala and so on. By reading the 330 letters of the gene in sets of threes, the ribosome makes a chain of 110 amino acids that go to make the human preproinsulin.
Genome is a lot more than genes
Genes, that is stretches of DNA that code for proteins, are just less than 1 per cent of the whole genome. The rest of 99 per cent of the genome is what is called a ‘non-coding’ region that does not produce proteins. Part of the non-coding regions are pseudogenes or genomic relics that have lost their ability to function. “The remaining segment of the non-coding genome was until now dismissed as ‘Junk DNA’,” says prof Krishnaswamy.
After all, a good cookbook not only provides receipts for making various dishes, but tips for the kitchen. How to cut an onion without irritating the eyes; what side dish is the best combination for the main meal; special cuisine ordained for a particular festival. Some dishes are good for breakfast and others are excellent for a light evening snack.
“Now we realise the non-coding regions are as important as the genes, for example, they regulate when and where certain genes are turned on or off,” says prof Krishnaswamy. Some proteins are needed when the organism is younger and others when it matures. Some are required after a meal and some others during the fasting time between meals.
Although every cell has the whole copy of the genome, not all proteins must be produced by it. Therefore, some part of the genome must be muted inside that cell. Consequently, not all genes must be active at all times and in every cell. Part of the genomic instructions in the non-coding region works as a switchboard to activate and deactivate the genes in a cell.
“Earlier, we were fixated on genes. Now we are wiser, even an alteration in non-coding regions can lead to disease,” says prof Krishnaswamy. Of course, not all changes in the non-coding region result in altered biology, but some changes can even be deadly. A change in the non-coding region may activate a gene and cause a protein to be produced in the wrong place or at the wrong time.
Alternatively, a variant can mute the production of an important protein when it is crucially needed. Pierre Robin syndrome, which results in the development of cleft palate and disfigurement of the face, is a result of a mutation in the non-coding region of the human genome.
Genomic jigsaw puzzle
One can open the book and easily start reading it letter by letter. But reading the 3 billion+ base pairs of the human genome from end to end and determining the precise sequence of nucleotides (As, Ts, Cs, and Gs) in the whole genome is demanding.
In the traditional sequencing technique, the DNA is first fragmented into random smaller pieces. The small segments are sequenced and the pattern of As, Ts, Cs, and Gs in it is determined. Using computer algorithms the smaller sequences are reassembled like puzzle pieces. Imagine shredding a thousand copies of Hamlet; and trying to assemble a copy from these pieces. The onerous task of genomic sequencing is akin to solving a giant jigsaw puzzle with millions of pieces. Like any intricate puzzle with thousands of pieces, it takes time to sequence a genome.
The genome contains not only genes, and non-coding regions. Intriguingly, more than half of the human genome is repetitive, with multiple copies of near-identical sequences, whose function is still a mystery. In particular, the telomeres (the ends of chromosomes), and centromere (a region of DNA that is important for the separation of sister chromosomes in cell division) are replete with repetitive regions. Telomeres, the regions at each end of the chromosome, for instance, have the sequence TTAGGG repeated three hundred to ten thousand times. Moreover, in five human chromosomes, the centromere is not in the middle but very close to one end, dividing the chromosome into one long and one very short arm.
These short arms are also full of repeats. To add to the woe, transposable elements, or what is popularly called jumping genes, another abundant type of repetitive genome sequence, are difficult to pinpoint. During cell division, they may jump from one location to another making it difficult to sequence and assemble.
Suppose the jigsaw puzzle is that of a bird, each piece would be slightly distinct and have an overlap with other pieces. One can determine the location of each of the pieces by looking for overlap and solving the puzzle. Now if the puzzle is a mowed lawn with monotonous patches of green grass. Many pieces of this puzzle would be near identical. Solving this puzzle is hard.
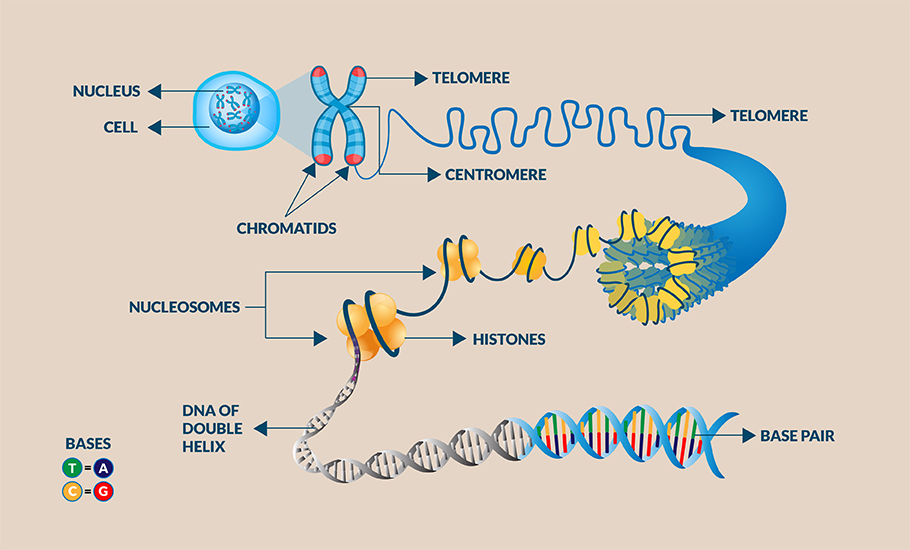
Completing the genomic puzzle
In 2000, when the Human Genome Project was deemed ‘essentially complete’, the researchers had not sequenced the full genome. About 15 per cent of the genome, almost 238 million letters, were missing from it. The human reference genome released in 2001 had around 1,50,000 gaps and many of them were filled in due course. The Updated reference genome GRCh38 released in 2013 had only 250 gaps, yet these gaps accounted for 8 per cent of the genome overall. “Until recently we lacked technologies to assemble the genome sequence of the repetitive regions,” says prof Krishnaswamy.
During the Human Genome Project, the researchers typically chopped the DNA with a maximum of 500 bases. The conventional technologies could read and sequence only such short fragments. With short segments of repetitive regions, it was not clear which piece will go where and hence these regions of the genome remained unmapped. Like the far side of the Moon, or the depth of the ocean floor, we were aware but essentially clueless.
Thankfully new technologies have helped in surmounting this problem. “The low complexity stretches and repeat-rich regions could be sequenced but could not be assembled. With Nanopore sequencer very long reads as long as 100s of KB or even an MB could be sequenced, so only now we could get to that 8 per cent,” explains Dr. Raja Mugasimangalam, founder and CEO, Genotypic Technology Private Limited.
Along with Oxford Nanopore, the other “long-read” sequencing technology called PacBio HiFi enabled the researchers to read thousands of nucleotides at length in one go. This is like simplifying 1,000 piece puzzle into 100 piece puzzle. “A total of six different methods were used to sequence these regions along with tools to assemble them,” says Prof Krishnaswamy.
The larger pieces of the puzzle are much easier to put together. It is more likely that they contain sequences that overlap. Armed with this new technology, researchers at T2T consortia sequenced the hitherto unmapped regions of the human genome to get a complete sequence of the human genome.
Science through social media
The Human Genome Project was a landmark achievement despite the fact not one chromosome was fully sequenced from end to end. Gaps continued to persist across the genome. To finish sequencing the remaining regions, fill in all the gaps, and prepare a first truly complete assembly of a human genome, Dr. Phillippy and Dr. Miga put out a call for scientists in 2019 to collaborate with them. The Telomere-to-Telomere Consortium (T2T Consortium) emerged as an open, community-based effort and eventually about 100 scientists from across various nations and institutions joined the all-out effort.
Within a few months, the Covid pandemic engulfed the world. Lockdowns were imposed, and travel and meeting became impossible. However, the T2T team was not dissuaded.
Harnessing the power of the social media platform, slack, a messaging app, the researchers established to join the collaboration. Persisting with toward their goal, the team put out a draft in May 2021 followed by peer-reviewed publications in March 2022.
“Increasingly, scientists are realising that the conventional system of submitting papers to journals and waiting for them to respond and for the papers to appear is very inefficient, especially where scientific frontiers are rapidly moving…While the larger implications of this are yet to be understood, there is no doubt in my mind that the increasing democratisation of science that this appears to be leaning towards is ultimately good for science,” says Gautam Menon, professor of Physics and Biology at Ashoka University.
New insights
With no apparent role, until recently, the repetitive regions of the genome and the anchor-less jumping genes were considered ‘junk DNA’. They were assumed to be some sort of vestigial remnant, like appendicitis, leftover from the long history of evolution.
To the tintinnabulation that so musically wells
From the bells, bells, bells, bells,
Bells, bells, bells—
From the jingling and the tinkling of the bells.
So goes Edgar Allan Poe’s most famous poem, “The Bells” (1849). The word ‘bells’ is repeated 62 times, not counting the word ‘bells’ in the title of this poem. Macduff in William Shakespeare’s Macbeth exclaims “O horror, horror, horror!” For these poets and authors, repetition is neither redundant nor waste but allows them to articulate the vehemence or emphasis.
The repetitive regions of DNA may have biological implications and the present achievement may help us decipher them. The centromere regions are key to cell division. When the cell divides, the centromere ensures that each of the two daughter cells gets the right number of chromosomes. If something goes wrong in the egg or the sperm, the babies are born with chromosomal anomalies that may result in dreaded diseases like Down syndrome or Turner syndrome. In the elderly, usually, the Y chromosome is not copied by the reproducing blood cells. With a more complete human genome, we can examine if the repetitive regions of the genome have any role to play in such ghastly ailments.
Work in progress
T2T-CHM13 is not the last word on the human genome. Due to the technological limitations, scientists estimate that 0.3 per cent of the sequence may still contain errors. Further, the T2T sequenced a genome that contained the X chromosome, and hence researchers are yet to sequence the Y chromosome. Even after the Y chromosome is sequenced, it would still be one set of 23 chromosomes, while humans have a pair. There still remain many a t to dash and i to dot.
Sequencing one genome is like taking a snapshot, while the life history of the genome is really like a film. As the sperm and egg fertilize and the first cell is born, the genome changes. With each replication, the genome is modified a wee bit. As one gets older, how the repeating regions change over time in a particular individual is yet to be fathomed. How the repeating regions differ between one person to another, from parent to offspring, is far more interesting. There is a long way to go.
All journeys have to take place by taking small steps. The T2T-CHM13 is a snapshot from one individual. “Having only genomes from a caucasian sample will lead to bias” points out prof Krishnaswamy. T2T Consortium has teamed up with a group called the Human Pangenome Reference Consortium to sequence genomes from around 300 people, as a first step, drawn from differing ethnic and geographical regions to get a better idea of human diversity. “Pangenome is only a way of trying to be politically correct and avoiding bias, but 300 is an arbitrary number. There are more different races and ethnicities,” reminds prof Krishnaswamy.